
Clustering History Data Penjualan Menggunakan Algoritma K-Means
Abstrak
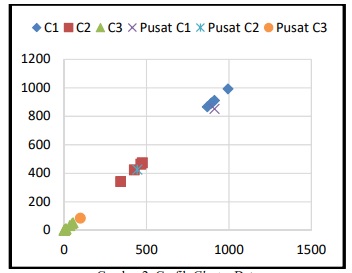
Perusahaan memiliki keinginan dalam mengembangkan peningkatan usahanya agar tidak tergerus dalam persaingan bisnis yang sangat ketat. PT. Baliyoni Saguna merupakan sebuah perusahaan yang bergerak dalam bidang teknologi informasi dan telekomunikasi yang saat ini sudah banyak membantu pelanggannya dalam memberikan solusi-solusi terbaik sesuai dengan kebutuhan pelanggannya. Kualitas produk menjadi faktor utama dalam menjaga agar pelanggan bisa bertahan dan merasa puas dari produk-produk yang diberikan oleh PT. Baliyoni Saguna. Produk-produk tersebut perlu dikaji kembali agar memiliki acuan dalam menciptakan produk terbaik. Clustering merupakan sebuah metode yang bisa digunakan dalam melihat tingkat penjualan yang telah dilakukan berdasarkan cluster yang terbentuk. Algoritma K-Means menjadi metode yang mampu mengolah history data penjualan yang dimiliki PT. Baliyoni Saguna dalam membentuk kelompok-kelompok sesuai dengan kategori item barang tersebut. Algoritma K-Means mampu memberikan kemudahan dalam mengolah data yang besar sehingga dapat diolah lebih cepat dan efisien. Hasil dari penerapan algortima K-Means, membentuk 3 cluster yang mewakili kategori sangat diminati, diminati dan kurang diminati. Pada kategori sangat diminati terdapat 5 jumlah item barang, kategori diminati terdapat 4 jumlah item barang dan kurang diminati terdapat 14 jumlah item barang. Hasil tersebut diharapkan dapat membantu dalam menciptakan barang yang berkualitas sehingga dapat menjaga kulitas produk serta kepuasan dari pelanggan.
Kata Kunci— Clustering, Algoritma K-Means, PT. Baliyoni Saguna.
##plugins.generic.usageStats.downloads##
Referensi
[2] A. Primandana, S. Adinugroho, and C. Dewi, “Optimasi Penentuan Centroid pada Algoritme K-Means Menggunakan Algoritme Pillar (Studi Kasus: Penyandang Masalah Kesejahteraan Sosial di Provinsi …,” … Teknol. Inf. dan Ilmu …, vol. 3, no. 11, pp. 10678–10683, 2020, [Online]. Available: http://j-ptiik.ub.ac.id/index.php/j-ptiik/article/download/6748/3264.
[3] A. W. Oktavia Gama, I. K. Gede Darma Putra, and I. P. Agung Bayupati, “Implementasi Algoritma Apriori Untuk Menemukan Frequent Itemset Dalam Keranjang Belanja,” Maj. Ilm. Teknol. Elektro, vol. 15, no. 2, pp. 21–26, 2016, doi: 10.24843/mite.1502.04.
[4] S. S. Nagari and L. Inayati, “Implementation of Clustering Using K-Means Method To Determine Nutritional Status,” J. Biometrika dan Kependud., vol. 9, no. 1, p. 62, 2020, doi: 10.20473/jbk.v9i1.2020.62-68.
[5] S. Saefudin and D. Fernando, “Penerapan Data Mining Rekomendasi Buku Menggunakan Algoritma Apriori,” JSiI (Jurnal Sist. Informasi), vol. 7, no. 1, p. 50, 2020, doi: 10.30656/jsii.v7i1.1899.
[6] I. Parlina, W. Agus Perdana, W. Anjar, and L. M.Ridwan, “Memanfaatkan Algoritma K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Center,” Memanfaatkan Algoritm. K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Cent. Untuk Clust. Progr. Sdp, vol. 3, no. 1, pp. 87–93, 2018.
[7] M. S. Mustafa, M. R. Ramadhan, and A. P. Thenata, “Implementasi Data Mining untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier,” Creat. Inf. Technol. J., vol. 4, no. 2, p. 151, 2018, doi: 10.24076/citec.2017v4i2.106.
[8] H. Priyatman, F. Sajid, and D. Haldivany, “Klasterisasi Menggunakan Algoritma K-Means Clustering untuk Memprediksi Waktu Kelulusan Mahasiswa,” J. Edukasi dan Penelit. Inform., vol. 5, no. 1, p. 62, 2019, doi: 10.26418/jp.v5i1.29611.
[9] I. S. Melati, L. Linawati, and I. A. . Giriantari, “Knowledge Discovery Data Akademik Untuk Prediksi Pengunduran Diri Calon Mahasiswa,” Maj. Ilm. Teknol. Elektro, vol. 17, no. 3, p. 325, 2018, doi: 10.24843/mite.2018.v17i03.p04.
[10] E. Ainun, W. Isti, and S. Fachri, “Implementasi Algoritma K - Means Clustering Tingkat Kepentingan Tagihan Rumah Sakit Di Pt Pertamina ( Persero ),” 2020.
[11] A. A. G. B. Ariana, I. K. G. Darma Putra, and L. Linawati, “Perbandingan Metode SOM/Kohonen dengan ART 2 pada Data Mining Perusahaan Retail,” Maj. Ilm. Teknol. Elektro, vol. 16, no. 2, p. 55, 2017, doi: 10.24843/mite.2017.v16i02p10.
[12] M. Pasek, A. Ariawan, N. P. Sastra, and I. M. Sudarma, “K- Mean s Clustering Dan Local Outlier Factor,” vol. 19, no. 1, 2020.
[13] N. G. Yudiarta, M. Sudarma, and W. G. Ariastina, “Penerapan Metode Clustering Text Mining Untuk Pengelompokan Berita Pada Unstructured Textual Data,” Maj. Ilm. Teknol. Elektro, vol. 17, no. 3, p. 339, 2018, doi: 10.24843/mite.2018.v17i03.p06.
[14] S. Butsianto and N. T. Mayangwulan, “Penerapan Data Mining Untuk Prediksi Penjualan Mobil Menggunakan Metode K-Means Clustering,” J. Nas. Komputasi dan Teknol. Inf., vol. 3, no. 3, pp. 187–201, 2020, doi: 10.32672/jnkti.v3i3.2428.
[15] G. Gustientiedina, M. H. Adiya, and Y. Desnelita, “Penerapan Algoritma K-Means Untuk Clustering Data Obat-Obatan,” J. Nas. Teknol. dan Sist. Inf., vol. 5, no. 1, pp. 17–24, 2019, doi: 10.25077/teknosi.v5i1.2019.17-24.
[16] Y. K. Siregar, “Analisis perbandingan algoritma,” vol. 2, no. 1, pp. 151–155, 2019.
[17] A. A. Rismayadi, N. N. Fatonah, dan Erfin Junianto, “Algoritma K-Means Clustering Untuk Menentukan Strategi Pemasaran Di CV. Integreet Konstruksi,” Jurnal Responsif, vol. 3, no. 1, pp. 30–36, 2021, [Online]. Available: http://ejurnal.ars.ac.id/index.php/jti/article/view/393.
[18] O. N. Pratiwi, “Analisa Perbandingan Algoritma K-Means, Decision Tree, Dan Naïve Bayes Untuk Sistem Pengelompokkan Siswa Otomatis,”Jurnal Ilmiah Teknologi Informasi Terapan., vol. II, no. 2, pp. 109–118, 2016.
[19] R. A. M. S. D. Yuhandri, “Perbandingan Algoritma K-Means Clustering Dengan Fuzzy C- Means Dalam Mengukur Tingkat Kepuasan Terhadap Televisi Dakwah Suaru TV,” Jurnal Teknologi dan Sistem Informasi Univrab, vol. 3, no. 1, pp. 10–21, 2018.
[20] M. Y. Rizki, S. Maysaroh, and A. P. Windarto, “Implementasi K-Means Clushtering Dalam Mengelompokkan Minat Membaca Penduduk Menurut Wilayah,” JUST IT Jurnal Sistem Informasi, Teknologi Informasi dan Komputer, vol. 11, no. 2, pp. 41–49, 2021, [Online]. Available: https://jurnal.umj.ac.id/index.php/just-it/article/view/5902.
[21] N. A. S. Damanik, Irianto, dan Dahriansah “Penerapan Metode Clustering Dengan Algoritma K-Means Tindakan Kejahatan Pencurian di Kabupaten Asahan.,”J-Com (Journal of Computer) vol. 1, no. 1, pp. 7–14, 2021, [Online]. Available: http:// jurnal.stmikroyal.ac.id/index.php/j-com

This work is licensed under a Creative Commons Attribution 4.0 International License

